
This is a practitioner account of building, breaking, and hardening a multi-agent AI system for outbound sales prospecting — deployed in Lyzr, integrated with HubSpot, Apollo, and Microsoft Outlook, and refined through seven passes over six weeks until it could be trusted in daily operations.
It covers what we designed, what failed, what we fixed, how the system operates today, and where the roadmap goes from here. The lessons apply to any enterprise team building coordinated agent systems for real workflows — regardless of the specific tools, CRM, or data sources involved.
In brief
SEVEN LESSONS
- Split agents whose jobs have different failure modes.
- The first agent sets the quality ceiling.
- Agents fabricate when guardrails are absent.
- Instruction bloat degrades reliability.
- RAG configuration is an active surface.
- Right-size models to role, not to the hardest job.
- Never optimise orchestration behaviour you cannot trace.
The operating reality
A ten-person outbound team. An addressable market of roughly 18,000 accounts. A preparation workflow that consumed the equivalent of more than two full-time headcount every week before any real selling happened.
The client was a B2B technology services firm selling into mid-market and lower-enterprise buyers across operations, finance, and technology functions. Their target universe ran to approximately 18,000 accounts across the geographies they covered. The sales team — ten people spanning SDRs and account executives, each carrying individual quota — was expected to work between 150 and 200 net-new accounts per week collectively. Pipeline was the primary constraint on revenue, and pipeline depended almost entirely on outbound quality.
Their workflow followed a pattern most outbound teams would recognise. For every new target account, a rep would research the company across public sources, scan for recent signals, search a contact intelligence platform for likely buyers, check HubSpot for existing records and prior activity, evaluate whether the account was worth pursuing right now, write an opening message shaped to the buyer's function, and log the activity back into the CRM.
That was six or seven distinct jobs compressed into one person's workflow. Each job touched a different system. Each had its own quality standard. Each competed for the same scarce resource — the rep's time.
In a disciplined team, the full sequence took 25 to 45 minutes per account. At the team's target cadence, that equated to 80 to 120 hours of preparation work per week across the group — before a single outreach message was sent. Under pressure, which was most weeks, corners were cut: research defaulted to a quick LinkedIn scan, CRM checks were skipped, outreach messaging fell back to templates. Salesforce's State of Sales research confirms the broader pattern — sales reps spend only about 30% of their time actually selling. The rest goes to research, administration, CRM entry, and internal coordination.
The cost was not just operational. The quality cost was worse. Research depth varied by rep. CRM records were inconsistent — duplicate accounts appeared regularly, and industry benchmarks suggest 10 to 30% duplication rates are typical for organisations without active data quality programmes. Contact information aged quickly in a market where buyers change roles every 18 to 24 months. Outreach response rates reflected the inconsistency: generic, research-light messages performing at typical cold outbound levels, while the occasional well-researched, personalised message would outperform by a factor of three or more.
For a team whose pipeline was the gating constraint on revenue, the preparation chain was structurally the most expensive part of the operation and the least reliable part of it. That was the business case for automation — not efficiency for its own sake, but converting prep hours into selling hours without losing the quality of the work being automated.
The brief was not "build a chatbot" or "add AI to the CRM." It was: automate the preparation chain — research, contact discovery, scoring, drafting, and CRM entry — while keeping humans in control of targeting decisions, messaging approval, and pipeline strategy.
That meant the architecture had to support role separation, confidence gating, human review, and structured handoffs between stages. It could not be one agent with a long prompt and a list of tools.
Why we built in Lyzr
The architecture required capabilities that a prompt-and-tools setup could not provide. Specifically, we needed:
- Per-agent configuration — independent model assignment, instructions, tools, and iteration limits for every agent.
- Supervisor-level orchestration — sequencing, confidence gating, and routing between specialist agents.
- Trace-level observability — visibility into which agent ran, what it returned, and where a run failed.
- Configuration snapshots — the ability to roll back any agent change without redeploying the system.
Lyzr provided those controls. Each agent runs as an independent unit with its own model, temperature, iteration limits, tool assignments, and instruction set. The configuration surface for each agent — model, role, goal, instructions, tools, and managed sub-agents — is directly accessible. A supervisor agent manages sequencing, confidence checks, and routing. When something breaks, we can inspect the trace, identify which agent failed and why, snapshot the current state, apply a fix, and verify — without touching the other agents in the pipeline.
That operational model shaped every decision in the build. Not because Lyzr was a feature requirement, but because the architecture would not have survived production without the ability to separate, observe, iterate, and roll back at the individual agent level.
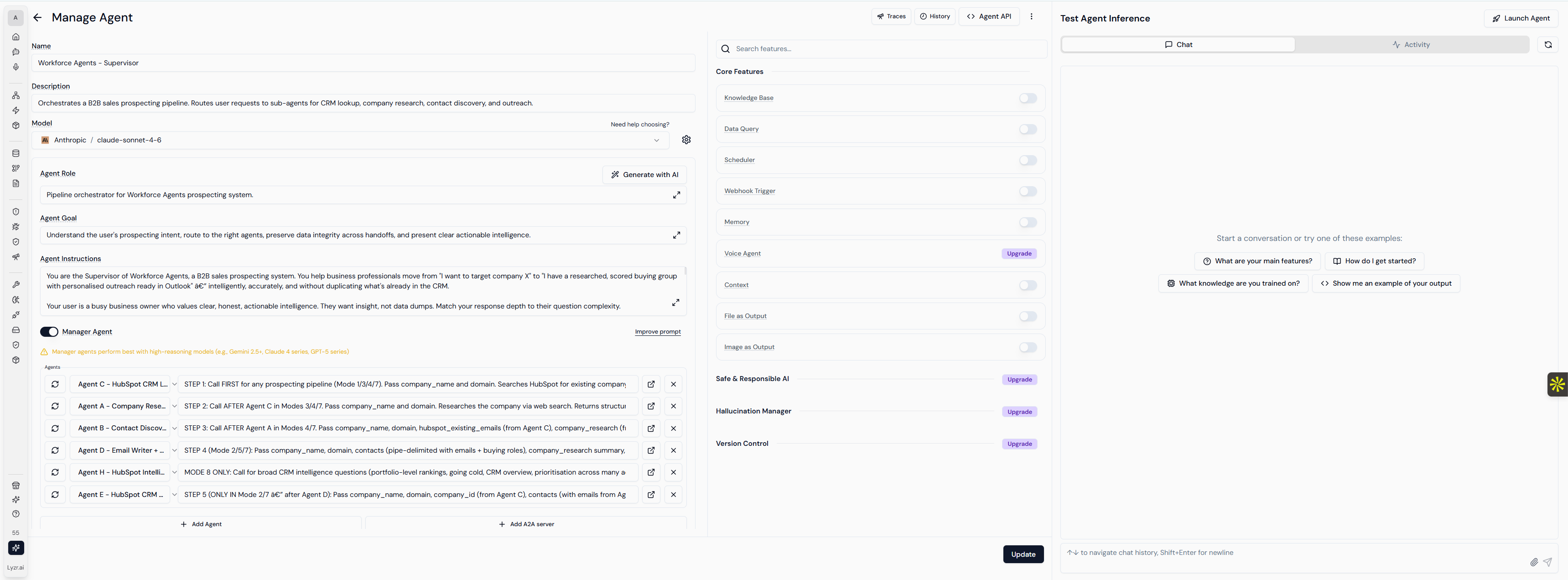
Figure 1. The supervisor agent's Manage Agent surface in Lyzr. Model, role, goal, instructions, managed sub-agents, core features, and guardrails (Safe & Responsible AI, Hallucination Manager, Version Control) all live on a single screen. Every specialist agent in the pipeline has the same surface. Changes are snapshotted and rolled back per agent, without redeploying the system.
What we designed
The system comprises seven specialist agents organised into three layers, with a pipeline that runs in sequence: CRM check, then research, then contact discovery and scoring, then email drafting, then CRM record creation. Supporting automations — a CRM summary service, a data validation layer, and scheduled refresh processes — keep the system's context current between pipeline runs.
Insight layer
- CRM Status Agent — queries HubSpot to determine whether the target account or its contacts already exist. Returns a five-state confidence rating (found exact, found probable, uncertain, not found after multi-check, search failed) before any downstream work begins.
- Account Research Agent — searches the web and reads full pages to build a structured company snapshot: business context, current signals, commercial relevance, and outreach implications.
- Contact Intelligence Agent — searches professional databases for likely buyers, maps the buying group, and scores each contact against a seven-dimension weighted model: problem ownership, initiative proximity, function relevance, buying power, champion potential, seniority, and novelty.
Execution layer
- Email Drafting Agent — produces first-touch messages using approved messaging rules sourced from a curated knowledge base. Messages follow strict tone, length, and forbidden-phrase rules, and adapt to each contact's buying role. Creates Outlook drafts only. Never sends automatically.
- CRM Writer Agent — creates or updates account and contact records in HubSpot with proper associations. Validates email addresses before writing. Skips contacts without verified emails entirely.
Orchestration layer
A supervisor agent controls the pipeline. It routes work through the sequence, enforces confidence gating at three decision points, prevents duplicate outreach when an account already exists, escalates ambiguous cases to human review, and maintains an audit trail. The system supports multiple operational modes — from a simple CRM lookup to a full pipeline run — so the seller can request exactly the depth of work they need for a given account.
Supporting automations
Production multi-agent systems do not run on agents alone. Ours includes a CRM summary service that refreshes weekly across the full account and contact database, maintaining a current snapshot of portfolio health, account ranking, and coverage gaps. A validation layer checks agent output quality against structural and data-integrity rules. These are not agents — they are operational services that keep the system's context current and its outputs trustworthy.
From the seller's perspective, the system presents as a single service. A rep queues an account. The pipeline returns a structured research snapshot, a scored contact list with buying-group mapping, an approved-style email draft in Outlook, and a logged CRM record — each traceable to the agent that produced it. The architectural complexity lives in the platform. The seller interacts with output, not orchestration.
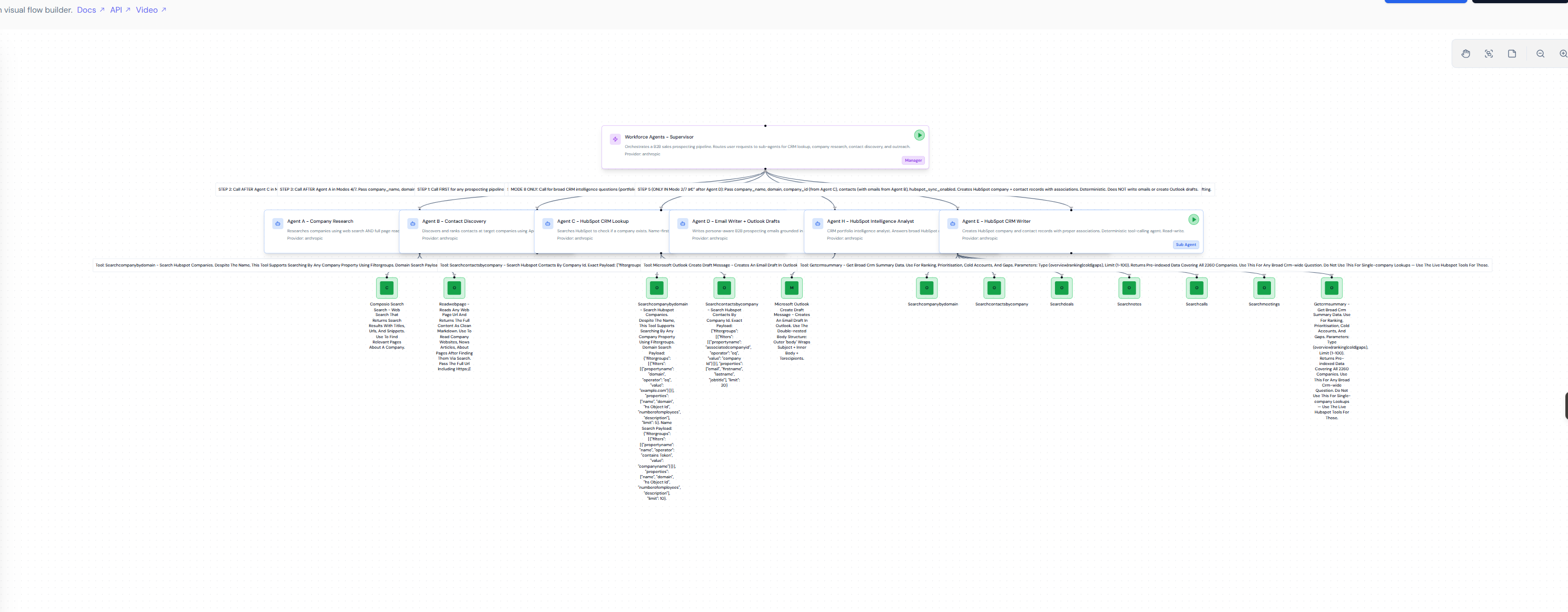
Figure 2. The production system as it runs in the Lyzr Manager canvas. A supervisor agent at the top routes work through seven specialist agents, each with its own model, tools, and instructions. The architecture is inspectable and reconfigurable without redeploying.
What broke — and what we fixed
Seven production lessons, in the order we learned them. Each one changed the architecture.
Lesson 1: One agent doing three jobs created cascading failures
In the first version of the system, a single agent handled email writing, CRM record creation, and Outlook draft creation. The instruction set for that agent was over 23,000 characters. It worked in testing. In production, the jobs interfered with each other.
When a CRM write failed — a 409 conflict on a duplicate record — the failure disrupted the email drafting process. When the Outlook API returned an unexpected payload structure, the agent would retry the CRM write instead of the draft. The jobs had different failure modes, different retry logic, and different validation requirements, but they were tangled inside one agent's context.
We split that agent into two in Lyzr: one for email writing and Outlook drafts, one for HubSpot record creation. The email agent's instructions dropped to around 5,200 characters — a 78% reduction. The CRM writer became a deterministic, tool-focused agent with minimal reasoning overhead. The split took less than an hour to implement because Lyzr allows agents to be created, configured, and attached to the supervisor independently.
Failures became isolated. A CRM conflict no longer affected email quality. An Outlook API issue no longer triggered unwanted CRM writes. Each agent could be debugged, tested, and improved on its own.
Takeaway: If an agent handles jobs with different failure modes, split them. The split costs almost nothing in latency but dramatically improves reliability and debuggability.
Lesson 2: Your CRM agent will lie to you — and the whole pipeline will believe it
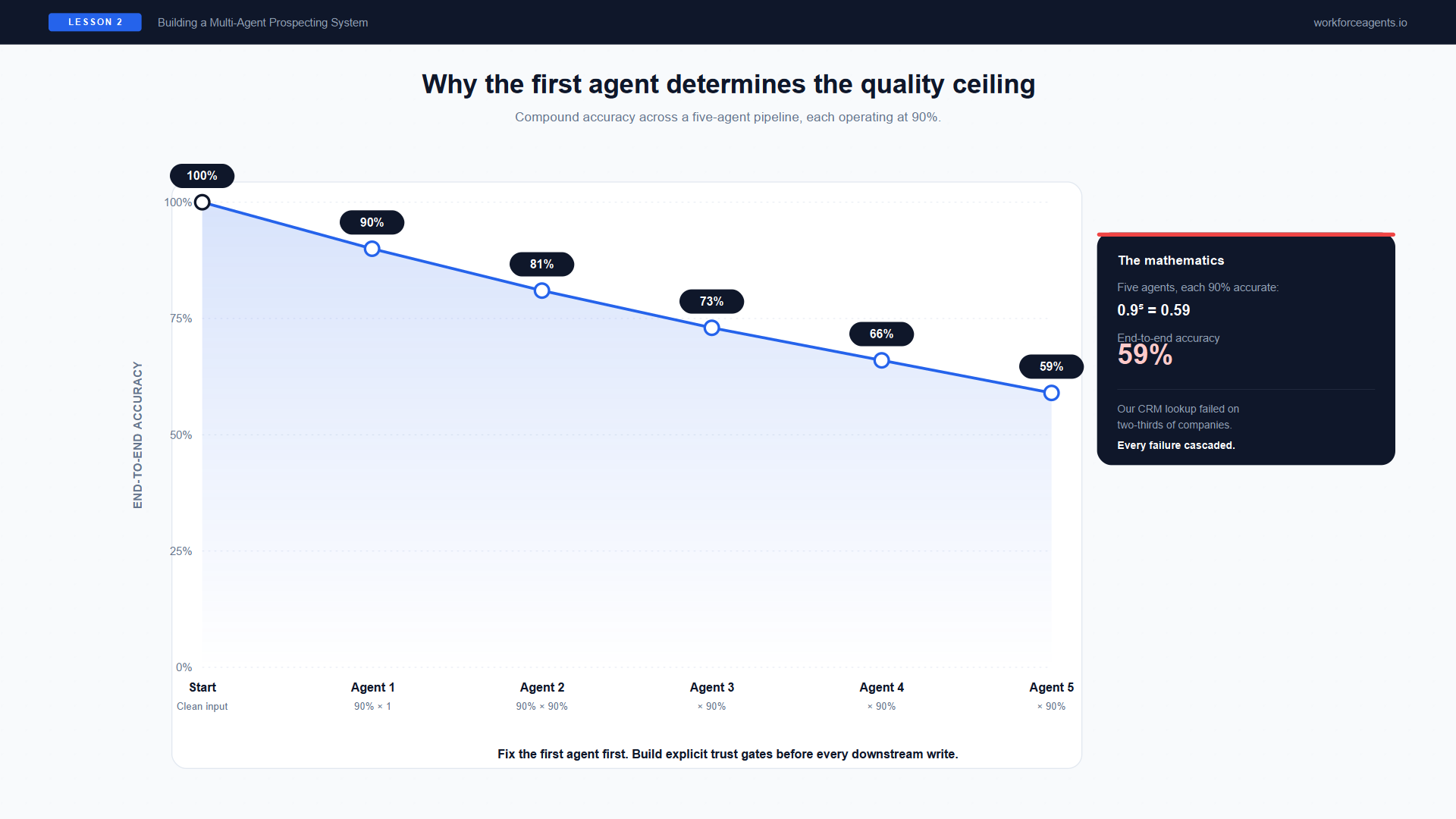
Figure 3. Compound accuracy across a five-agent pipeline. Five agents each operating at 90% accuracy yield 59% end-to-end — our CRM lookup was failing two-thirds of the time, and every failure cascaded.
The CRM Status Agent's job was simple: check whether a company exists in HubSpot before the pipeline creates new records. In the first deployment, it used domain-based search — appending .com or .com.au to the company name and querying HubSpot's domain field.
That approach failed for roughly two-thirds of the companies in a HubSpot instance carrying over 12,000 active account records. Most mid-market companies do not have domains that match their trading name in a predictable way.
The downstream impact was immediate. When the CRM agent reported "not found" for a company that actually existed, the supervisor trusted that result. The pipeline proceeded to create a new company record, new contact records, and new email drafts — all duplicating work that was already in the system. We discovered garbled contact records in HubSpot created from masked upstream data that the pipeline had treated as real.
The mathematics are sobering: a five-agent pipeline where each agent is 90% accurate yields only 59% end-to-end accuracy. Our CRM agent was failing on two-thirds of lookups, and every failure cascaded.
We rebuilt it with a multi-strategy search cascade: domain search first, then name-based token search, then a cleaned-name search stripping common suffixes. We added the five-state confidence model and a supervisor-level trust verification rule that blocks all downstream writes when the CRM status is uncertain or failed. In Lyzr, the confidence states are visible in the agent trace, so when a lookup returns "uncertain," we can see exactly which strategies were attempted and why.
Takeaway: The first agent in the chain determines the quality ceiling for everything downstream. Invest disproportionately in its accuracy and build explicit trust gates between agents.
Lesson 3: AI agents fabricate data when guardrails do not exist
This was the most expensive lesson.
The contact discovery agent searched Apollo for contacts at target companies. When Apollo's credit allocation was low, it returned masked last names (characters like "Me***r") and null email addresses. The email drafting agent, receiving contacts with missing emails, did what language models do when given incomplete data — it filled in the gaps. It constructed plausible-looking email addresses from garbled names and company domains.
Real Outlook drafts were created to fabricated addresses. Real HubSpot records were created with garbled names. We found contacts like "Louise Mebur" in the CRM — the actual person was Louise Mercer, but the masked data had been treated as a real name.
This is not an edge case. Research on LLM-based agent hallucination identifies the "snowball effect" as a primary risk for production systems: a minor data gap in an initial step cascades through subsequent tool calls, with each agent treating the fabricated output as ground truth.
We built a six-check anti-fabrication system: asterisk detection in names, null-email filtering, domain validation, minimum field requirements, a search-status flag for partial data, and a hard gate that skips any contact without a verified email address. We also added input validation to the email drafting agent — it verifies that contact data meets minimum quality thresholds before composing anything.
Takeaway: Every agent that writes to an external system needs input validation, not just output validation. Assume the upstream agent's data is wrong until verified.
Lesson 4: Instruction bloat is the silent killer
Over seven refinement passes, the system's total instruction set grew to more than 72,000 characters across all agents. Each fix added weight. Each edge case added a rule. Each rule added context that the model had to attend to on every single run.
The agents became less reliable — not because the instructions were wrong, but because there was too much to hold. The "Lost in the Middle" study confirmed the mechanism: language models suffer significant accuracy drops when critical information sits in the middle of their context window. Longer instructions actively degrade performance.
We rewrote every agent's instructions with a purpose-first approach. Instead of threat-based rules ("NEVER do X, ALWAYS check Y, CRITICAL: do not forget Z"), we used goal-oriented framing ("Your job is to do X. Here is how. Here is why."). The total instruction set dropped from around 72,000 to around 30,000 characters — a reduction of roughly 58%, and still tightening with each refinement pass. In Lyzr, each agent's instruction length is visible in its configuration, making bloat easy to spot. Agents became more consistent, not less, despite having fewer rules.
Takeaway: Unusually long instructions are often a sign that one agent is carrying too much architectural weight. If you are adding rules to compensate for complexity, consider splitting the agent instead.
Lesson 5: Knowledge base retrieval quality shapes output quality
The email drafting agent sourced its messaging guidance from a curated knowledge base covering positioning, use cases, industry angles, and objection handling. In the initial configuration, retrieval used basic similarity search — returning the five most similar chunks to the query.
The problem was that those five chunks were often near-duplicates. Five slightly different versions of the same value proposition. A Head of Operations and a VP of Sales received essentially the same pitch.
We switched to Maximum Marginal Relevance (MMR) retrieval, added a relevance score threshold, and set a diversity parameter to balance query relevance with chunk dissimilarity. The same five retrieval slots now surface different angles: industry context, implementation patterns, outcome data, capability framing, and objection handling. In Lyzr, RAG parameters are configurable per agent without code changes. We could test a new retrieval configuration in minutes and compare output quality directly.
Email quality improved noticeably. Messages started adapting to the buyer's function and the company's specific situation rather than repeating a single generic proposition.
Takeaway: RAG configuration is not "set and forget." Retrieval strategy, diversity tuning, and relevance thresholds are active surfaces that directly shape output quality.
Lesson 6: Right-sizing models to agent roles changes the economics
In the first deployment, every agent ran on the same frontier model. The supervisor — which makes routing and orchestration decisions involving genuine reasoning — ran on the same model as the CRM lookup agent, which performs a deterministic database search.
When we right-sized models to match job complexity, the cost picture changed substantially. The supervisor runs on a larger model with stronger reasoning capability. Procedural agents — CRM lookups, record creation — run on smaller, faster models optimised for reliability.
In Lyzr, model assignment is a per-agent configuration field. We could test a smaller model on the CRM writer, run five pipeline executions, compare the output, and either keep the change or roll back — all within a single session. No redeployment, no code changes, no risk to the other agents.
Takeaway: Match model capability to job complexity, not to the hardest job in the pipeline. The cost savings compound at scale.
Lesson 7: Never optimise what you do not understand
Late in the deployment, we observed that the supervisor agent was making two synthesis calls at the end of each pipeline run instead of one. It appeared to be waste — two calls doing the same work. We added a rule to compress the completion path into a single pass.
Three immediate test runs failed. One produced empty output. One caused the email agent to ask clarifying questions instead of drafting. One skipped the CRM lookup and research agents entirely, going straight to email drafting with placeholder names.
The trailing dual-synthesis calls were load-bearing. They were performing a format pass, a draft verification step, or a safety check — functions invisible in the trace data. We had optimised away a behaviour we did not understand.
We rolled back within minutes using a pre-change configuration snapshot saved in Lyzr. The system recovered immediately. But the lesson was permanent: in a multi-agent system, optimisation without comprehensive trace understanding is dangerous. We now require at least four consistent traces before modifying any orchestration behaviour.
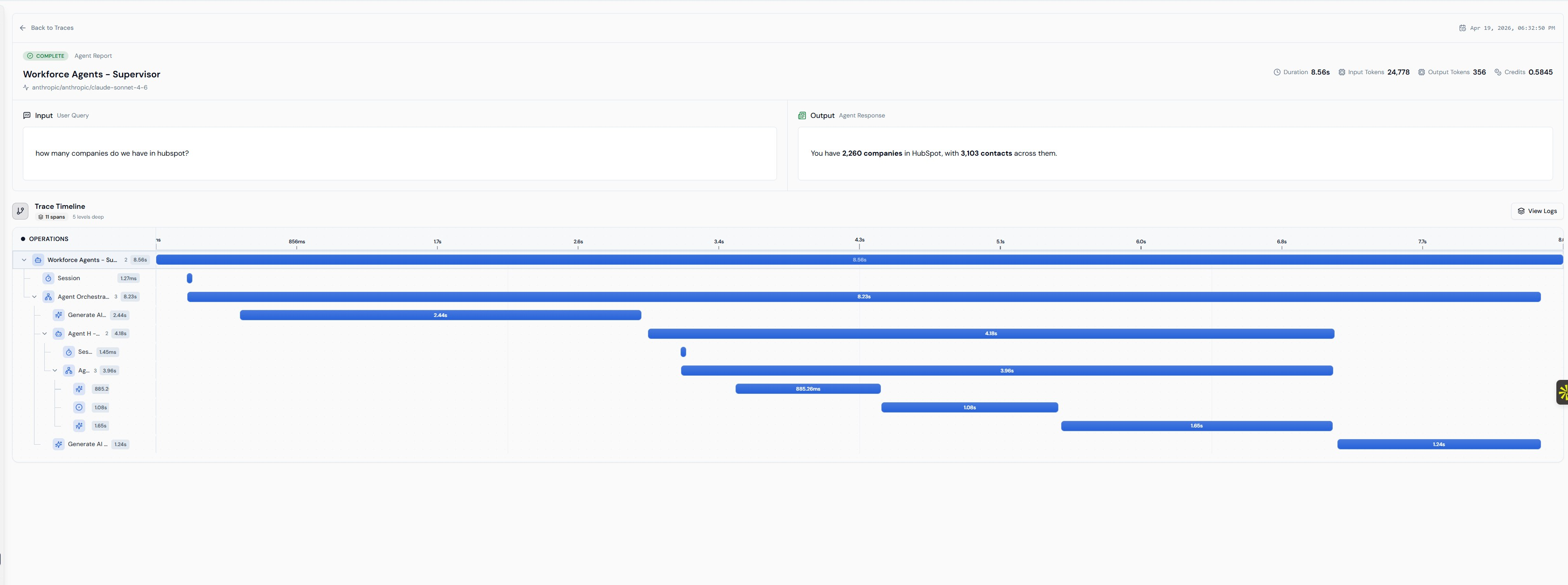
Figure 4. A complete supervisor run in the Lyzr trace view — eleven spans, five levels deep, agent-by-agent durations, token counts, and credits. Optimisation decisions are made against this evidence surface, not against intuition about what an agent 'should' be doing.
Takeaway: In multi-agent systems, what looks like waste may be load-bearing. Never compress a path you cannot fully explain. Keep configuration snapshots so you can roll back instantly.
Where we are now
The system has been through a full pressure-test audit covering ten core areas: model alignment, loop protection, data quality handling, inter-agent handoffs, email quality, knowledge base retrieval, output formatting, CRM trust verification, fabrication defences, and orchestration stability. All ten areas met the operational standard. Three targeted hardening fixes were applied during the audit — none were breaking issues, but each made the system materially more resilient.
CURRENT OPERATIONAL STATE
- Seven agents running on Claude models end-to-end, with model tiers matched to role complexity
- Multiple operational modes from simple CRM lookup to full pipeline
- CRM summary service refreshing weekly across 12,000+ accounts and 18,000+ contacts
- Data validation layer checking agent output quality against structural rules
- Configuration snapshots taken before every change, enabling instant rollback
- Total instruction set at roughly 30,000 characters across all agents (down from 72,000)
- All changes applied and verified through Lyzr's agent configuration API
In routine operation, the pipeline runs without cascade failures. Confidence gating holds at the three decision points. The anti-fabrication system catches the masked-data cases that previously contaminated the CRM. Reliability is not measured as a single headline number — it is observed across the trace surface, agent by agent, with each hardening pass lifting the weakest link rather than optimising an average.

Figure 5. Live monitoring across all seven agents — credit consumption, average latency, token efficiency, error rate, and latency trends. Right-sizing and optimisation decisions are grounded in this surface rather than anecdote.
What the system does not do yet
The current system does not click "send." Humans still press the button on every outreach message. The pipeline stops at preparing the draft in Outlook, creating the CRM record, and staging the research.
This is an intentional design choice to preserve trust while the organisation acclimates to the automated preparation speed.
Autonomous sending remains a future-state option once the approval edit-rate drops near zero.
What the roadmap looks like from here
A system like this does not reach production and stop evolving. The architecture was designed to support iteration, and the roadmap reflects the natural maturity path of a coordinated agent system that is already handling the core workflow.
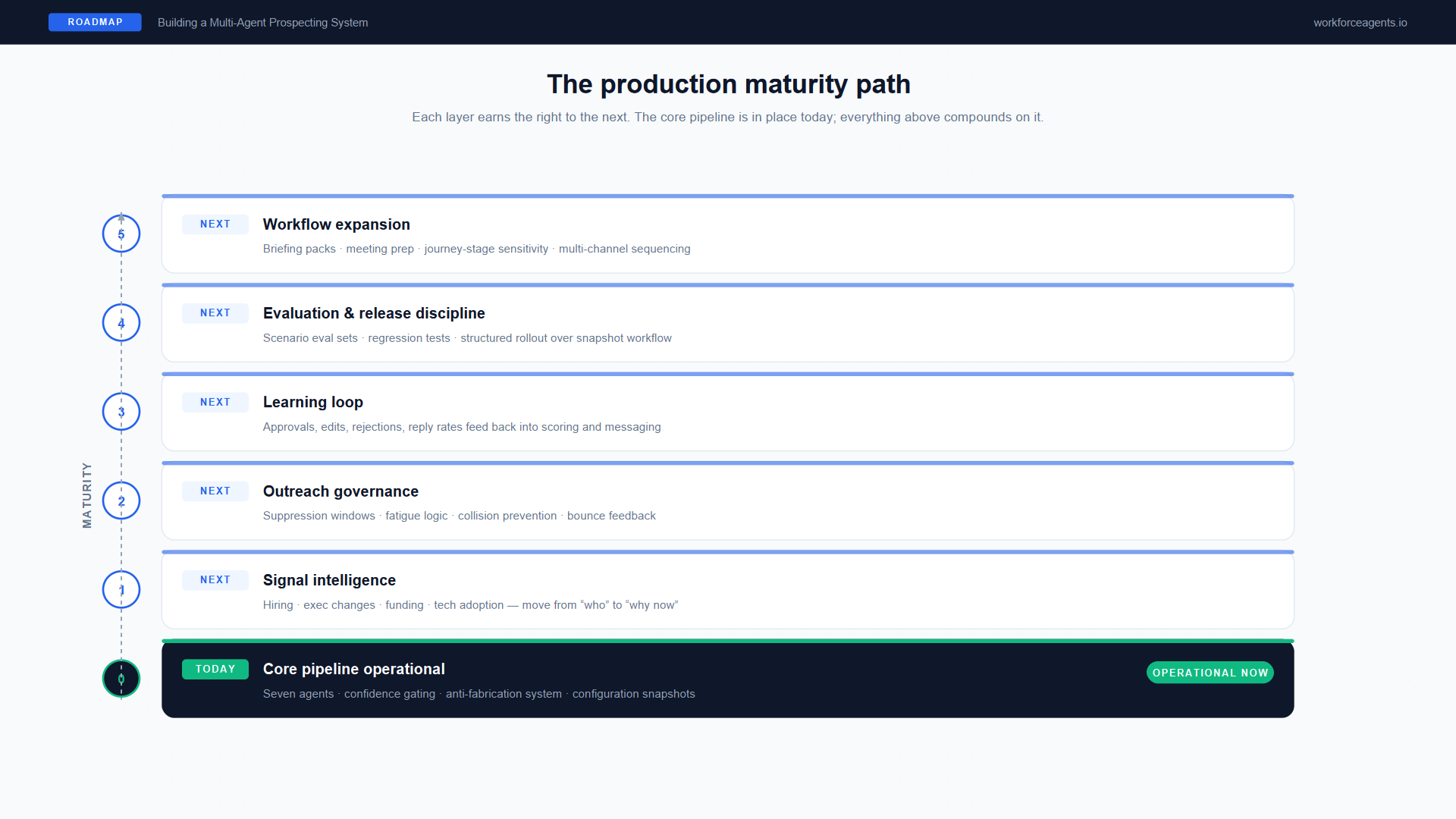
Figure 6. The production maturity path. The core pipeline is operational today; each layer above compounds on it without requiring a rebuild of the foundation.
Signal intelligence
The current system researches accounts using web search and page reading. The next layer adds structured buying signals: hiring activity in target functions, executive changes, funding or expansion announcements, and technology adoption indicators. The commercial goal is clear — move from "who and what" toward "why now," so that sellers spend their time on accounts where timing makes outreach likely to land, not just accounts that fit the profile on paper.
Early evidence suggests the performance difference is substantial — teams acting on intent signals within 24 hours consistently outperform those relying on static lists. The architecture already supports this extension. It requires richer input signals to the research agent, not a redesign of the pipeline.
Outreach governance
The current system prevents duplicate CRM records and skips contacts without verified emails. The next layer adds outreach history awareness: suppression windows to prevent re-contacting accounts too soon, fatigue logic to limit touchpoints within a time period, collision prevention between human and agent actions on the same account, and bounce or invalid-contact handling that feeds back into contact quality scoring.
These are not feature additions. They are governance layers that determine whether the system earns trust from the sales team or creates friction that leads reps to route around it.
Learning loop
Today, the system drafts messages and creates CRM records. The human seller reviews, edits, approves, or rejects. But the system does not yet learn from those decisions.
The next maturity layer closes that loop. Approved drafts become positive signal for the messaging model. Edited drafts surface where the knowledge base or scoring logic needs refinement. Rejected drafts identify systematic gaps. Reply rates, bounce rates, and meeting-booked outcomes — when tracked — create a feedback surface that allows the system to improve its scoring, messaging, and prioritisation over time.
This is the layer that transforms the system from a preparation tool into one that gets better at selecting, scoring, and messaging with every cycle. Most production teams still rely on human review as their primary quality mechanism. Closed-loop learning from downstream business outcomes — reply rates, meetings booked, deals created — remains an emerging pattern and a significant source of differentiation for teams that implement it.
Evaluation and release discipline
As the system matures, changes to prompts, models, tools, and orchestration logic must be validated before deployment — not just tested manually. That means scenario-based evaluation sets covering known-good and known-bad cases. It means regression testing that catches when a model update or instruction change degrades an agent that was previously working. And it means structured release discipline that protects the production system from well-intentioned changes that turn out to break something downstream.
Lyzr's configuration snapshots and per-agent iteration model make this operationally feasible. Each change can be tested in isolation, compared against prior behaviour, and rolled back if it regresses. But the evaluation sets themselves — the "what does good look like" reference cases — must be built and maintained by the team operating the system.
Workflow expansion
The current system covers account preparation and first-touch outreach. The natural expansion path extends toward seller briefing packs (aggregating research, scoring, CRM history, and recommended talking points into a single pre-call summary), meeting preparation, journey-stage sensitivity (adapting approach based on whether an account is cold, warm, or re-engaged), and multi-channel sequencing beyond email.
Each of these expansions follows the same architectural principle: decompose the new workflow into distinct jobs, assign each to a specialist agent, and connect them through the orchestration layer. The value compounds — each new capability extends what the seller can do in a given hour without requiring a rebuild of the core pipeline.
What we would do differently next time
Start with the CRM agent. Its accuracy determines the quality ceiling for the entire pipeline. We spent more time fixing cascade failures from bad CRM lookups than on any other single issue.
Build input validation before the first production run. The anti-fabrication system should have been in place from day one, not built reactively after finding garbled records in HubSpot.
Write instructions at 50% of the length you think you need. Every refinement pass that reduced instruction length improved reliability. Purpose-first, goal-oriented instructions outperform threat-based rule lists.
Split agents earlier. The "one agent, three jobs" phase cost us the most rework. If two functions have different failure modes or different validation requirements, they should be separate agents from the start.
Budget for knowledge base content as a first-class workstream. The email drafting agent's quality is directly bounded by the depth and diversity of its knowledge base. Thin coverage in a target industry produces thin outreach.
Keep configuration snapshots religiously. Every change, no matter how small, should be preceded by a snapshot. The ability to roll back in minutes saved us multiple times.
Key takeaways for enterprise teams
These lessons are specific to our deployment, but the underlying patterns generalise. Whether a team uses this CRM or a different one, this contact database or another, this orchestration environment or a different platform — the production challenges are consistent. Role separation, trustworthy data flow, input validation, observability, and safe iteration matter more than any particular vendor or stack choice.
- The first agent in the chain is the most important agent in the system. Invest disproportionately in its accuracy and build trust gates between every stage.
- Assume upstream data is wrong until verified. Input validation on every agent that writes to an external system is not optional — it is the primary defence against fabrication cascades.
- Instruction length is a leading indicator of architectural fragility. If an agent's prompt is growing unusually long, treat that as a signal it may be carrying too much architectural weight.
- Right-size models to roles. Procedural agents do not need frontier reasoning. Supervisors do. The cost difference compounds at scale.
- Optimise only what you can fully trace. In multi-agent systems, what appears redundant may be structurally necessary. Require strong evidence before compressing any orchestration path.
- Production systems need supporting infrastructure, not just agents. Summary services, validation layers, scheduled refreshes, and evaluation sets are not optional extras — they are what keep the system trustworthy between runs.
- The gap between "works in a demo" and "runs in production" is where most architectures fail. Build for the messy cases from day one.
This system is not finished. No production AI system ever is. But it is operational, auditable, and improving with every run — which is exactly what a coordinated agent architecture, deployed in a platform that supports production-grade iteration, is designed to deliver.
Platform context: This system was built and operates on the Lyzr AI platform, with HubSpot CRM, Apollo contact intelligence, Microsoft Outlook, and Jina Reader as integration targets. Supporting automations run on Replit.
Research basis: Salesforce State of Sales (6th edition), Liu et al. "Lost in the Middle" (Transactions of the ACL), Google DeepMind agent scaling research, LangChain State of Agent Engineering survey (2025), Stanford Enterprise AI Playbook (March 2026).