
Gartner predicts that more than 40% of agentic AI projects will be cancelled by the end of 2027 — not because the models are weak, but because the architectures around them cannot survive real workflows. Single agents fail in production because most enterprise workflows are not single tasks. They are chains of interpretation, routing, validation, execution, exception handling, and human judgment spread across multiple systems. A single agent can look capable in a demo, but once it meets real workflows, real data, and real operational risk, the architecture often becomes the failure point.
The thesis
A lot of enterprise AI deployments still begin with the same hidden assumption: if one capable agent can complete the workflow in a test environment, one capable agent can run it in production.
That assumption breaks quickly.
In a prototype, a single agent often looks elegant. One interface. One prompt loop. One place to add tools. One unit to evaluate. For narrow tasks, that can be exactly the right architecture. But in production, most workflows are not narrow. They cross systems, roles, approval boundaries, and risk thresholds. They contain ambiguity. They contain bad data. They contain exceptions. They contain steps that should be automated and steps that should remain human.
That is where single-agent architectures start to fail. Not because the model is weak, but because the workflow is stronger than the loop trying to hold it.
This distinction matters more in 2026 than it did in 2024. According to LangChain's State of Agent Engineering survey of 1,340 practitioners, 57% now have agents running in production — up from 51% the year before — and quality has emerged as the number-one production barrier, cited by 32% of respondents. The market has enough real deployment experience to understand that agent success is not mainly about whether the model can reason. It is about whether the system around that reasoning is structured to survive handoffs, uncertainty, policy, and operational load.
The most useful way to frame the issue is simple: a single agent is often good at doing one job well. Enterprise workflows usually contain several jobs. When those jobs are collapsed into one loop, reliability drops, trust erodes, and the human team starts rebuilding the missing structure manually.
Key takeaway: Single agents fail in production when one model loop is forced to carry a workflow that actually needs role separation, explicit control, and human checkpoints.
What actually breaks in production
The visible symptom is usually disappointing output. The real problem is workflow fragility.
When enterprise teams say an agent "didn't work in production," they rarely mean the model could not produce a plausible answer. More often, they mean one of five things happened.
1. The agent loses control of the workflow
The agent can reason, but it cannot reliably decide what should happen next across multiple stages of work.
This is where single-agent systems begin to blur analysis, decision-making, execution, and validation into one opaque loop. The same agent is expected to inspect the situation, choose a path, call the right tool, interpret the result, decide whether confidence is high enough, and then act. That can work for simple tasks. It becomes brittle when the workflow has more than one meaningful branch.
The result is usually inconsistency. The agent takes the right path in one case and the wrong one in another. It over-escalates. Or under-escalates. Or calls the right tool in the wrong order. Or keeps going when it should stop.
2. The agent carries too much context
As workflows get more complex, a single agent accumulates too many responsibilities, too many tool descriptions, too many policies, too many state variables, and too many exceptions.
This is not just a prompting problem. It is an architectural problem backed by hard research. The "Lost in the Middle" study published in Transactions of the ACL showed that language models suffer significant accuracy drops when critical information is placed in the middle of their context window — with some models falling from near-perfect retrieval to below 40% accuracy depending on position. Databricks' research on long-context RAG performance found that most models only show increasing performance up to 16,000-32,000 tokens, with reliability degrading substantially beyond that range. A 2025 study published at EMNLP Findings demonstrated that context length alone degrades performance materially — even when irrelevant tokens are replaced with whitespace — confirming that the problem is structural, not just a matter of retrieval quality.
In production, the symptom is often simple: the system looks fine on happy paths and erratic on messy ones. The model is not broken — it is drowning.
3. Verification is too weak
Production systems do not just need outputs. They need outputs that can be trusted enough to act on.
A single-agent architecture often makes verification an afterthought. The same agent that generates the output is also implicitly treated as sufficient to validate it. That is where costly errors creep in. A record gets updated when it should not. A workflow continues with low confidence. A draft looks plausible but is based on incomplete context. A policy edge case slips through because no distinct verification step existed in the architecture.
In low-risk environments, that may be tolerable. In customer operations, finance, support, legal, or regulated workflows, it is not. PwC's 2025 AI Agent Survey found that executive trust in AI agents drops sharply with stakes — from 38% for data analysis tasks down to just 20% for financial transactions. When verification is invisible, trust cannot form.
4. Exceptions have nowhere clean to go
Enterprise work is full of awkward cases:
- duplicate records
- conflicting signals
- missing data
- unclear ownership
- approvals that depend on business context rather than deterministic rules
Single-agent systems often handle these badly because they have no clean structural place to route uncertainty. Everything becomes one more instruction inside the same loop. "If X, then maybe Y, unless Z." Over time, the system becomes less like a controlled workflow and more like a pile of conditional behaviour hidden in a prompt.
That is one reason pilots often degrade as they scale. The first ten cases look manageable. The next thousand expose the long tail.
5. Humans stop trusting the system
This is the production failure that matters most.
A human team does not abandon an AI system because it is imperfect. They abandon it because it becomes unpredictable, opaque, or expensive to check. If the system gets three important calls wrong, people start routing around it. If no one can see where the mistake entered the workflow, trust drops faster. If the human reviewer ends up reconstructing the logic manually each time, the system has not removed work. It has relocated it.
LangChain's survey found that 89% of teams with agents in production have implemented observability — and 62% have detailed step-level tracing. That investment reflects a hard lesson: without visibility into what the agent did and why, operational trust never forms. Once adoption stalls, usage falls. Then the business concludes that "the agent didn't work," when the deeper truth is that the architecture never earned operational trust.
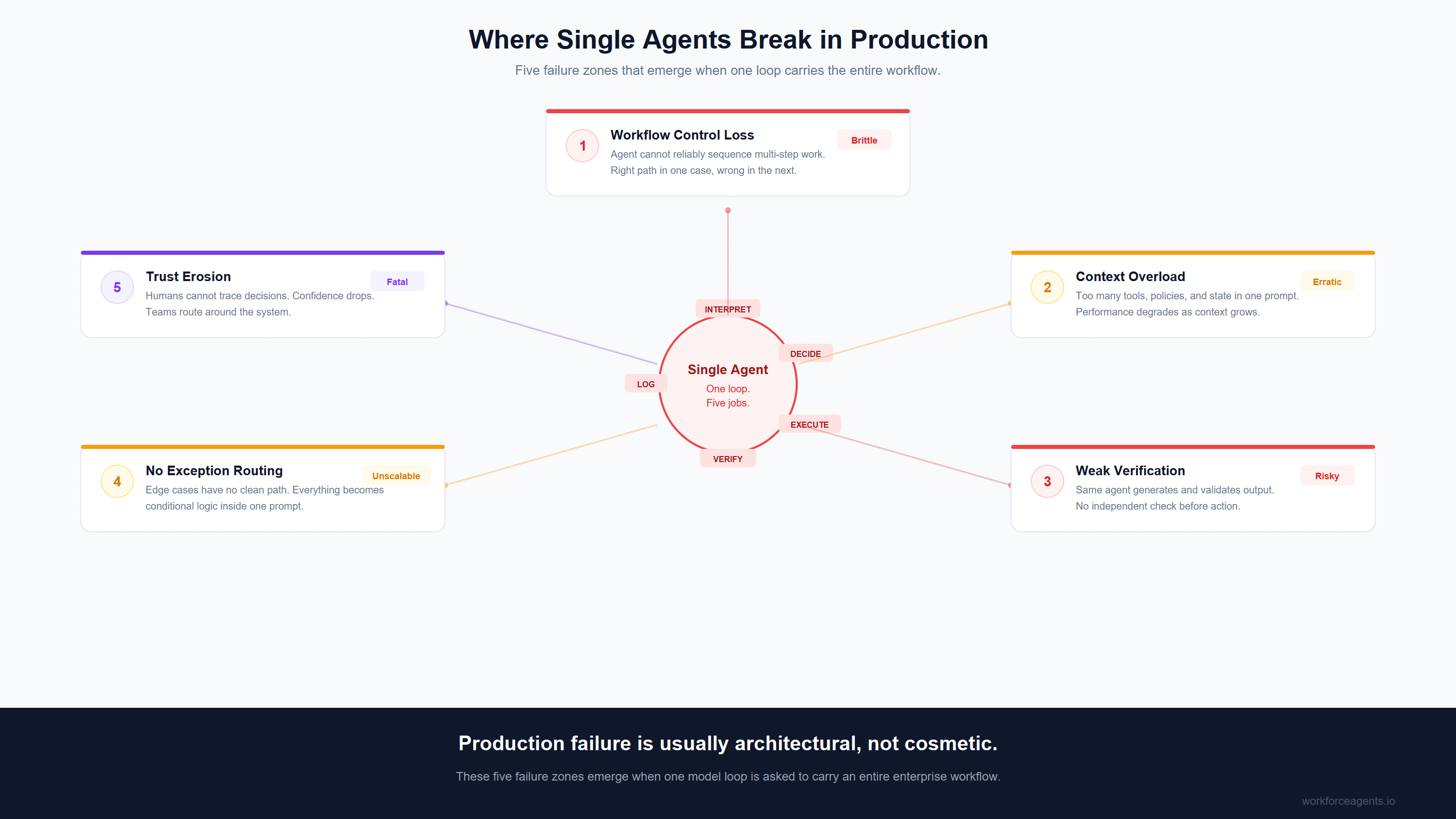
Key takeaway: Production failure usually comes from workflow fragility, not from the absence of a smarter model.
Why this is happening more often in 2026
There are two reasons this issue is becoming more visible now.
The first is that organisations are finally putting agents into higher-stakes workflows. In the last two years, many teams proved that agents can search, summarise, draft, and call tools. That was the prototype era. By 2026, the harder question is not whether an agent can do something once. It is whether the system can do it repeatedly, safely, and observably enough to sit inside day-to-day operations. S&P Global found that the average organisation scraps 46% of AI proofs-of-concept before reaching production — and only 48% of AI projects make it into production at all. The gap between "it works in a demo" and "it runs in operations" is where single-agent designs most often break.
The second is that the industry has learned more about agent failure at the workflow level. Anthropic's influential "Building Effective Agents" guidance published in December 2024 led with a principle that many teams initially resisted: start by "finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all." OpenAI's Agents SDK introduced structured primitives for handoffs, guardrails, and tracing — an implicit acknowledgment that single-loop designs are insufficient for production. Recent research on multi-agent failure patterns also reinforces that many failures cluster around system design, inter-agent coordination, and verification rather than raw language capability alone.
That does not mean "more agents" is always better. Google Research found that multi-agent coordination delivers an 81% improvement on parallelisable tasks but causes up to 39-70% degradation on sequential reasoning tasks. The answer is not reflexive complexity — it is architectural honesty about what the workflow actually requires:
- orchestration
- observability
- evaluation
- guardrails
- clear tool boundaries
- explicit handoffs
- human review where it matters
Those are system properties, not prompt decorations.
Key takeaway: By 2026, the market has enough real deployment experience to see that agent reliability is an architecture problem before it is a model problem.
When a single agent is still the right choice
This article is not arguing that single agents are bad. In many cases, they are the right architecture.
A single agent is often the best option when:
- the workflow is narrow and bounded
- the number of tools is small
- the decision logic is simple
- the cost of error is low
- output can be checked easily
- there are few exceptions
- the workflow does not cross multiple ownership or approval boundaries
For example, a single agent may be perfectly appropriate for:
- answering a tightly scoped internal question
- summarising a document set
- classifying straightforward requests
- drafting low-risk first-pass content
- handling a contained workflow with one or two deterministic tool calls
In these cases, adding orchestration too early creates unnecessary complexity. It increases latency, cost, and maintenance overhead. Anthropic's own production guidance makes this point directly: "optimising single LLM calls with retrieval and in-context examples is usually enough" for many applications. One of the clearest lessons from recent production experience is that teams should not introduce multi-agent patterns just because they sound advanced — the overhead of coordination is only justified when the workflow genuinely demands it.
That matters for Workforce Agents' positioning too. The point is not that every problem deserves a coordinated agent team. The point is that real business workflows often do.
The right question is not "should we use one agent or many?" It is "what is the smallest architecture that can be trusted in production for this workflow?"
That framing avoids both extremes:
- over-building with unnecessary coordination
- under-building with a single agent that cannot reliably carry the workflow

Key takeaway: The best architecture is the smallest one that can meet the operational standard of the workflow.
What works instead
When single agents fail, the answer is usually not "replace them with more intelligence." It is "separate the jobs inside the workflow."
In practice, that means decomposing the workflow into distinct roles such as:
Interpretation What is happening here? What signals matter? What context is relevant?
Decisioning Should this continue? Which path? Is confidence high enough?
Execution What action should be taken? Which system? What output?
Verification Did it meet the standard? Was it safe? Does a human need to approve?
Logging and Learning Every step recorded. Every decision traceable. Every outcome measured. Audit trail enables iteration, compliance, and trust-building over time.
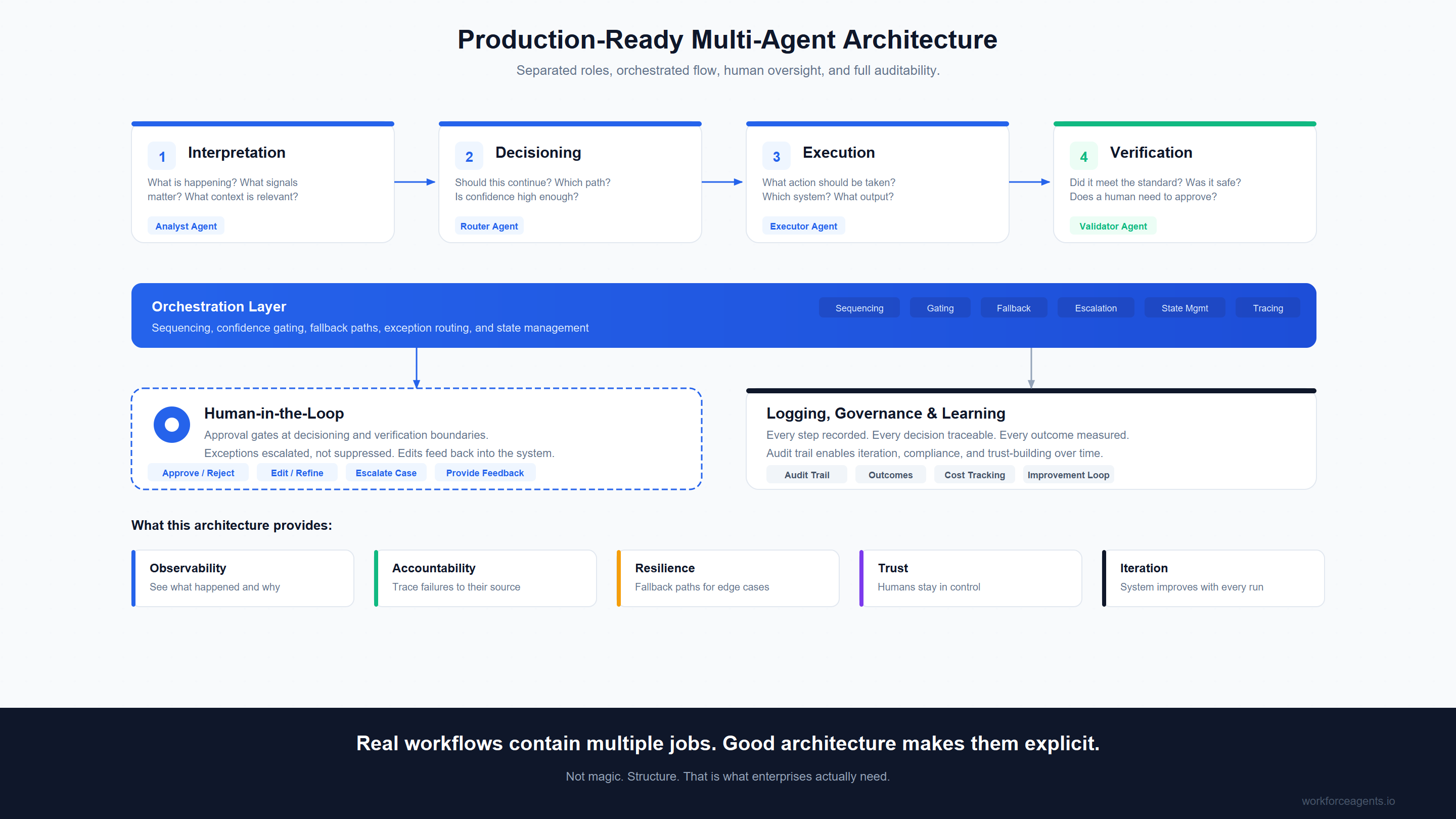
Once those jobs are made explicit, a different architecture becomes possible. A router handles decisions. An analyst handles interpretation. An executor handles drafting. A validator handles compliance. They are coordinated by a central orchestrator that knows when to stop, when to escalate to a human, and how to log the whole chain.
The complexity does not disappear, but it becomes manageable. If the executor drafts a bad email, you fix the executor. If the router sends an ambiguous case to a human instead of an agent, the system worked as intended.
That is how you build trust in production. You do not just build a smarter agent. You build an architecture that survives the workflow.
Sources & Further Reading:
- Gartner, Predicts 2024: Artificial Intelligence (2024)
- LangChain, State of Agent Engineering (2025)
- Nelson F. Liu et al., Lost in the Middle: How Language Models Use Long Contexts, Transactions of the Association for Computational Linguistics (2024)
- Databricks, Retrieval-Augmented Generation (RAG) Long Context Performance (2024)
- EMNLP Findings, Context Length Degradation Studies (2025)
- PwC, 2025 AI Agent Survey: Trust and Adoption (2025)
- S&P Global, AI Production Readiness Report (2025)
- Anthropic, Building Effective Agents (2024)
- Google Research, Scaling Laws for Multi-Agent Collaboration (2025)