The hard part of enterprise AI isn't the model. It's everything between the model and the business outcome.
Most enterprise AI strategies still begin with the wrong question: "Which model should we use?"
In 2023, that was the right question. In 2026, it is the least important one an enterprise can ask. Because once AI moves from pilot to production — touching customer operations, revenue workflows, compliance, reporting, execution — intelligence stops being the bottleneck. Architecture does. And architecture, unlike intelligence, has to survive reality.
Because when it doesn't, the failure shows up in revenue, operations, and customer experience — not just system logs.
The false assumption
A lot of organisations are implicitly making the same mistake: they treat choosing a powerful model as if it were the same thing as designing an AI strategy.
It isn't.
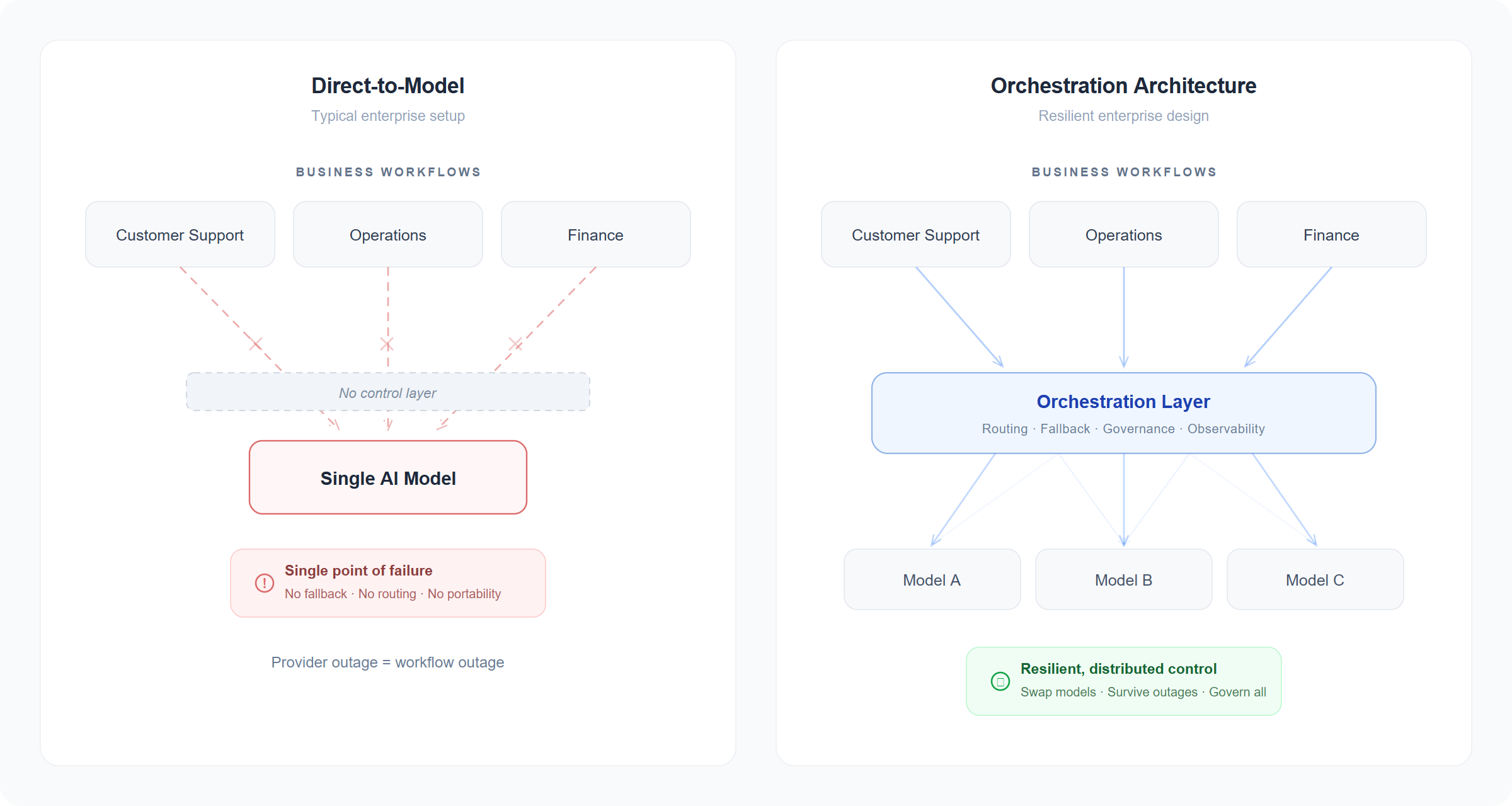
Direct-to-model is a deployment pattern, not an architecture. It works in pilot. It does not hold at scale.
A model provider gives you inference. In the best cases, it gives you hosting, security options, and developer tooling. It does not give you a resilient operating layer for enterprise workflows. That requires something else: routing, fallback, model portability, observability, governance, system integration, and workflow orchestration. It requires a control layer above the model.
This is the unglamorous half of enterprise AI — and where most of the risk actually lives. An AI stack with no control layer isn't an enterprise architecture. It's a single vendor's SLA wearing your company's logo.
Put simply: direct-to-model is single-engine architecture. Orchestration is twin-engine. Both can fly. Only one is certified for the weather.
Why this is surfacing now
The past six months have made the point concrete. Every major provider has had visible disruptions.
Anthropic's status page shows eight separate incidents in April 2026 alone — elevated error rates on Haiku 4.5, Sonnet 4.6, and Opus 4.6, connector failures, and a full Claude.ai outage on April 13. OpenAI's status history shows over a dozen ChatGPT and API incidents in April 2026 alone — authentication failures, API errors, and complete endpoint outages. Google Cloud has reported elevated error rates on the Vertex AI Gemini API. Azure's March 9–10 incident (tracking ID 8GCS-858) took GPT-5.2 out across seven regions — Australia East, Central US, East US 2, Korea Central, Norway East, Sweden Central, UK South — for roughly twenty hours.
None of that means those platforms are weak. It means distributed AI systems behave like distributed systems. Enterprises have already solved this shape of problem in other layers — databases behind abstraction, workloads spread across regions, messages routed through brokers that survive a broker failure. AI is simply the newest layer to reach production scale, and the same engineering discipline applies.
Every minute the model is down, your operations revert to work you thought you'd already eliminated.
Four risks of a single-provider strategy
1. Concentration risk. If a business-critical workflow depends on one provider endpoint, it inherits that provider's entire outage profile. A chatbot can fail gracefully. A customer-service pipeline, claims process, or revenue workflow usually cannot. In practice, that means revenue-impacting workflows are now coupled to infrastructure you don't control. And these failures rarely happen at 2 a.m. They happen in the middle of the business day, during peak demand, when the cost of manual fallback is highest.
2. Architectural drag. Model markets are moving too fast for a static architecture. New models arrive, prices shift, capability gaps close, governance requirements evolve. Wired tightly to one provider, every change becomes a migration project instead of a routing decision. The economics alone make the case: for models of equivalent performance, inference prices have fallen roughly 10× per year since 2021. Andreessen Horowitz calls this "LLMflation"; Epoch AI finds the pace has accelerated since early 2024. At the same time, newer reasoning models consume far more tokens per query than their predecessors. The net cost of getting work done now depends entirely on which workloads run on which models — and an architecture that can't shift traffic catches neither the falling prices on one side nor the efficiency gains on the other.
3. Audit blind spots. Enterprise AI isn't just about generating responses. It's about knowing what happened, why it happened, which tools were invoked, which policies applied, and how to improve behaviour over time. Direct-to-provider integrations tend to log what the provider logs — which is rarely what a CISO, regulator, or internal auditor actually needs. "The provider has that" is not an answer that survives contact with a serious audit.
4. The last-mile problem. Real enterprise value rarely lives in the model call itself. It lives in the workflow around it: retrieving context, selecting tools, enforcing business rules, handing off between agents, connecting to systems of record, and maintaining continuity across sessions. Models don't do that work. Workflows do.
For regulated sectors and for regions with data-residency constraints, these four risks compound. A single-provider architecture is often, by extension, a single-geography architecture — and with the EU AI Act's high-risk provisions taking effect in August 2026, an increasingly expensive corner to design yourself into.
What this looks like in practice
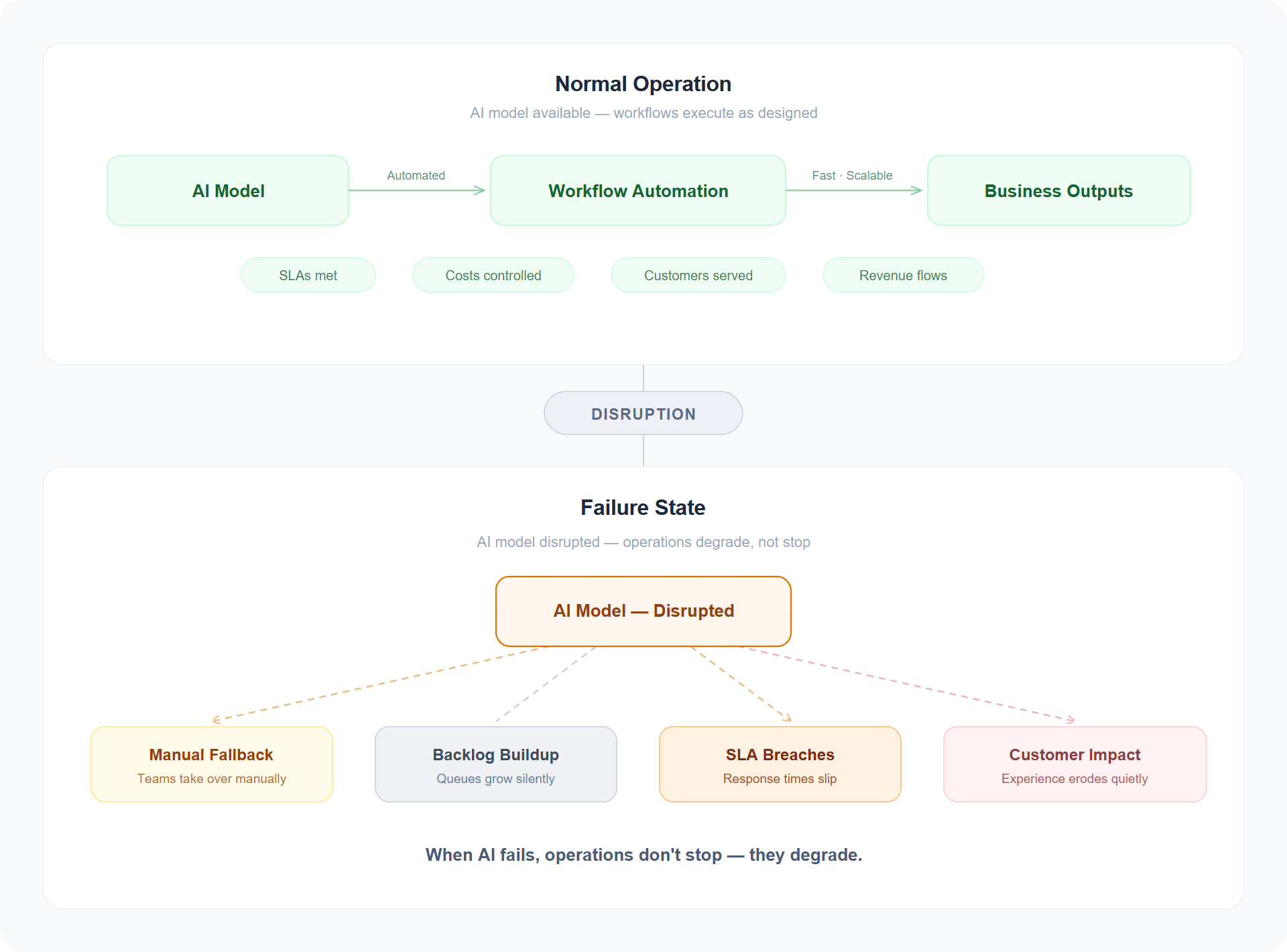
Consider a global consumer brand that runs its customer-service triage through a single AI provider. A two-hour disruption on a peak retail afternoon doesn't stop the business — it quietly removes the intelligence layer from every downstream workflow. Tickets queue. Agents revert to manual routing. Service times slip. By the time the provider is back, the contact centre has breached its SLA for the quarter.
The real cost isn't the model bill. It's senior people doing work the system was supposed to do, customers who weren't served on time, and the internal incident report explaining why one vendor's bad afternoon became the company's. The cost of a provider's bad afternoon is paid in customer patience you don't get back.
The economics reinforce the point. Industry research consistently shows that high-impact IT outages cost large enterprises upwards of $300,000 per hour in direct and indirect losses — and for organisations running AI-dependent customer operations, the figure can be significantly higher. But the less visible cost is often larger: 75 days of revenue recovery, according to CFO surveys, and an average 2.5% stock-price decline following a significant incident. When AI is embedded in customer-facing workflows, the cost of a two-hour disruption is not two hours of lost productivity. It is weeks of eroded trust, missed targets, and internal capital spent explaining what happened instead of building what comes next.
That is the texture of single-provider risk. Not catastrophe — attrition.
What an orchestration layer actually does
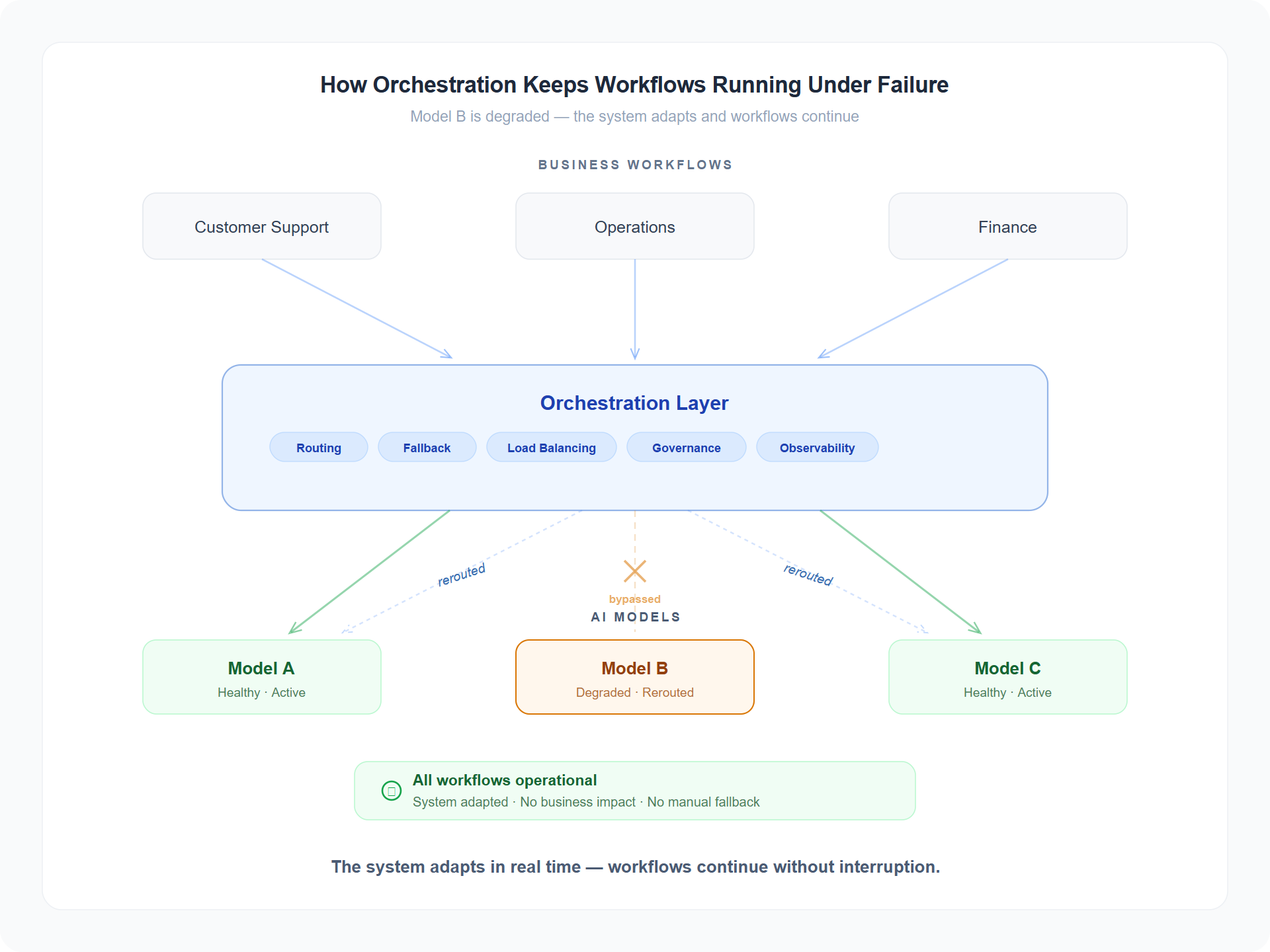
The four risks have four mitigations, and together they describe what enterprises are actually buying when they buy "AI orchestration" — whether they describe it in those words yet or not.
- Concentration risk is mitigated by routing and fallback.
- Architectural drag is mitigated by model portability.
- Audit blind spots are mitigated by centralised observability and policy.
- The last-mile problem is mitigated by workflow orchestration — the part that turns an inference call into a business outcome.
This is not vendor positioning — it is a structural shift in the category. In December 2025, Forrester formally recognised the "agent control plane" as an emerging market category. IDC now describes model routing as a foundational enterprise AI pattern. Hyperscaler platforms (Microsoft's Copilot Studio, Google's Vertex AI Agent Builder) are building orchestration, governance, and agent-management directly into their offerings, while independent vendors are framing their platforms as a control plane above the model. Both camps are converging on the same architectural insight from opposite sides. In our work with enterprise teams, that convergence has become the most reliable signal of where the category is heading.
But isn't orchestration just another dependency?
Fair question. Every abstraction layer is a new point of failure, and anyone selling "resilience" while introducing a new vendor should expect scepticism.
The honest answer is yes, and it is a trade worth making — because an orchestration layer is a thinner dependency than a model. You can deploy it in your own cloud environment. You can run it across regions. You can swap the underlying model provider without rewriting business logic. None of that is true of the model itself.
You are not eliminating risk. You are replacing opaque risk you don't control with thin, observable risk you do.
Beyond resilience
Resilience is only the entry ticket. The larger value of an orchestration layer is that it lets enterprises optimise continuously instead of committing rigidly.
Different workflows have different needs. Some require the strongest reasoning available today. Some need sub-second latency. Some need the lowest possible per-token cost. Some need a model deployed in-region for compliance. Some need predictable tool use more than creative generation. The best architecture is not "pick one model and standardise everything around it." It is a governed orchestration layer that can choose intelligently, switch safely, and keep the business operating as the market shifts underneath it.
The winners in enterprise AI will not be the organisations that picked the smartest model in 2024. They will be the organisations that route the right work to the right model at the right moment — and can change that decision next quarter without rebuilding anything.
The model market in 2026 is not going to get simpler. It is going to keep fragmenting — more providers, more open-source options, more specialised models, more regional and compliance-bound deployments. The enterprises that took this shape of problem seriously in databases, messaging, and cloud compute already know the answer.
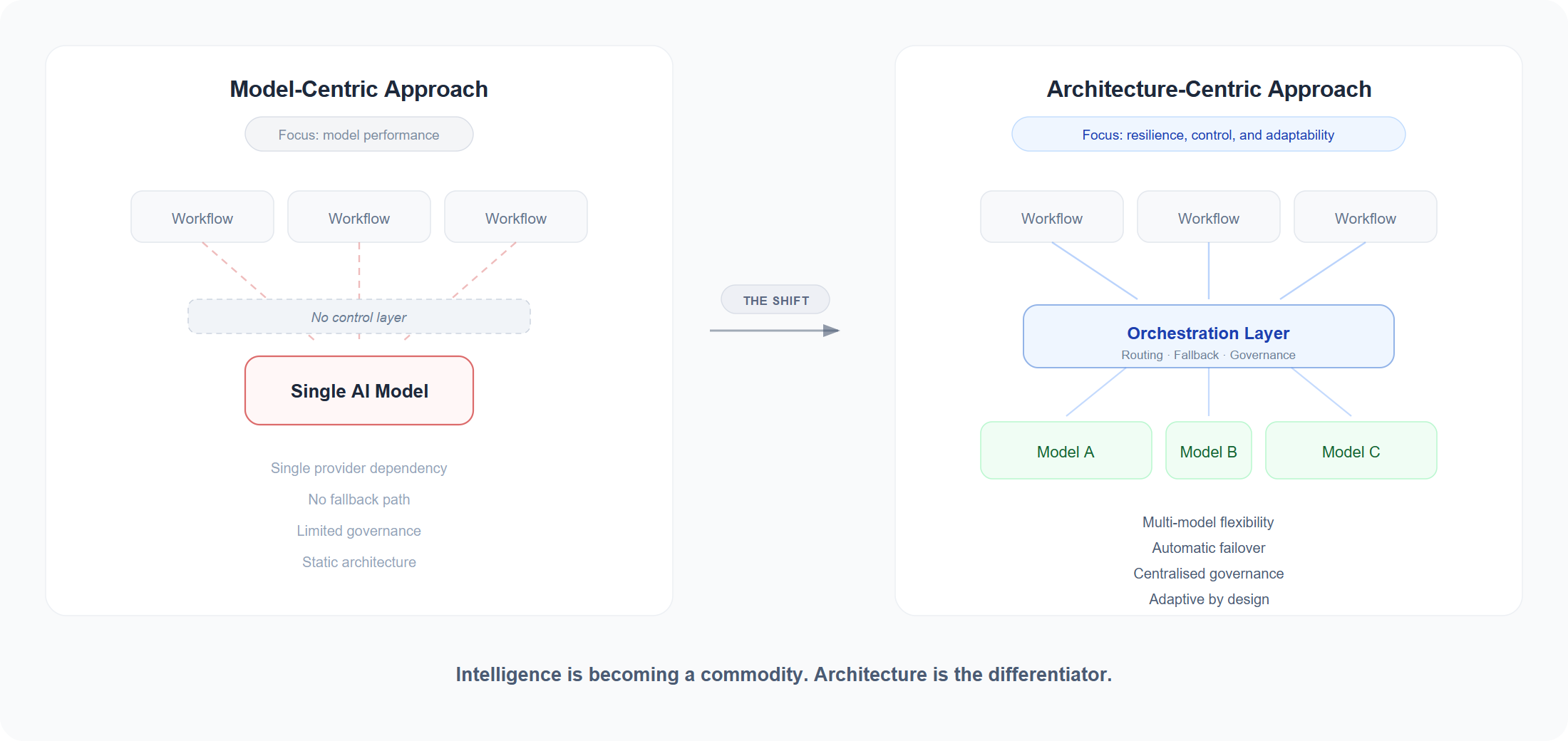
A model provider gives you intelligence.
An orchestration layer gives you operational resilience, governance, and the freedom to adapt.
For prototypes, the distinction is academic. For production, it is existential.
The real risk isn't choosing the wrong model once.
It is building a critical workflow that fails every time your chosen provider does — and having no second move.
The question is no longer "which model is best?" It's "how do we build systems that don't break when models do?"
Intelligence is becoming a commodity. The architecture around it is not — and that is where the next decade of enterprise AI will be won or lost.
The model gets the headline. The architecture decides whether the business runs.